Face Stabilization by Mode Pursuit for Avatar Construction
Image Vision Computing 2018

Avatars driven by facial motion capture are widely used in games and movies, and may become the foundation of future online virtual reality social spaces. In many of these applications, it is necessary to disambiguate the rigid motion of the skull from deformations due to changing facial expression. This is required so that the expression can be isolated, analyzed, and transferred to the virtual avatar.
The problem of identifying the skull motion is partially addressed through the use of a headset or helmet that is assumed to be rigid relative to the skull. However, the headset can slip when a person is moving vigorously on a motion capture stage or in a virtual reality game. More fundamentally, on some people even the skin on the sides and top of the head moves during extreme facial expressions, resulting in the headset shifting slightly. Accurate conveyance of facial deformation is important for conveying emotions, so a better solution to this problem is desired.
In this paper, we observe that although every point on the face is potentially moving, each tracked point or vertex returns to a neutral or “rest” position frequently as the responsible muscles relax. When viewed from the reference frame of the skull, the histograms of point positions over time should therefore show a concentrated mode at this rest position. On the other hand, the mode is obscured or destroyed when tracked points are viewed in a coordinate frame that is corrupted by the overall rigid motion of the head. Thus, we seek a smooth sequence of rigid transforms that cause the vertex motion histograms to reveal clear modes. To solve this challenging optimization problem, we use a coarse-to-fine strategy in which smoothness is guaranteed by the parameterization of the solution. We validate the results on both professionally created synthetic animations in which the ground truth is known, and on dense 4D computer vision capture of real humans. The results are clearly superior to alternative approaches such as assuming the existence of stationary points on the skin, or using rigid iterated closest points.
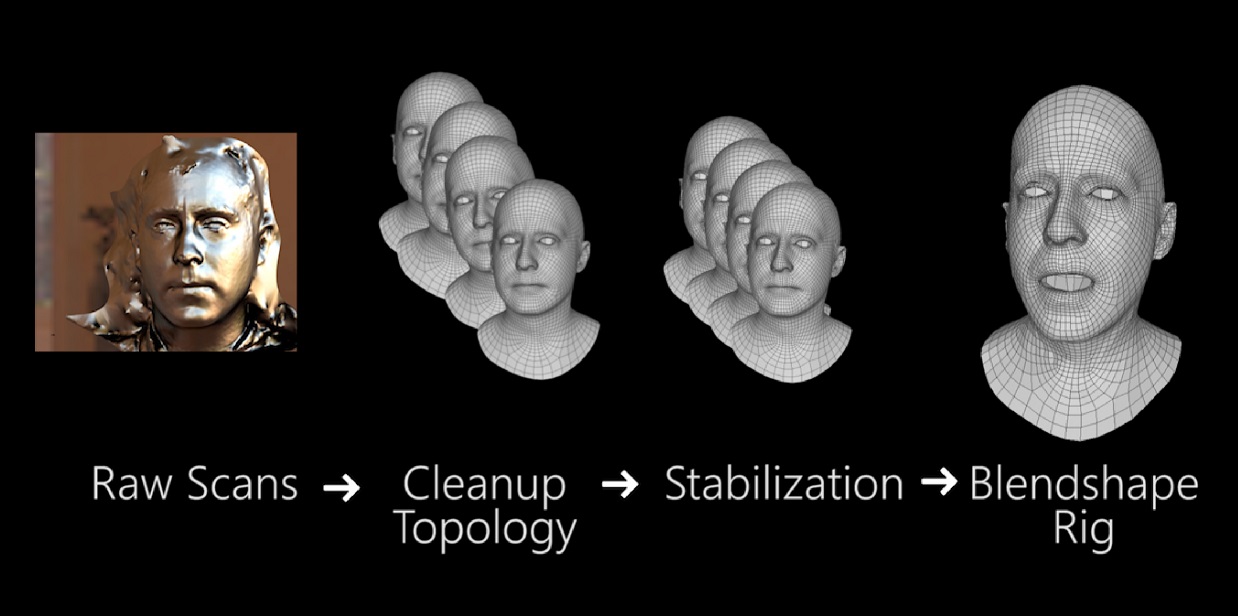
A high-level view of constructing an avatar model, showing the role of stabilization.
LAMARRE, Mathieu, LEWIS, J.P. and DANVOYE, Étienne. Face Stabilization by Mode Pursuit for Avatar Construction, Image Vision Computing 2018
You can download the paper here: PDF format (3.9MB .pdf)
